State of the art, by the numbers
Most memory systems claim to be better. Supermemory is measurably ahead — first place across all three independent benchmarks the field uses to grade AI memory.| Benchmark | What it measures | Supermemory |
|---|---|---|
| LongMemEval | Long-term memory across sessions, with knowledge updates | 81.6% — #1 |
| LoCoMo | Fact recall across long conversations (multi-hop, temporal, adversarial) | #1 |
| ConvoMem | Personalization and preference learning | #1 |
What makes Supermemory different
Most “memory layers” are a vector store that retrieves the nearest chunk. Supermemory is an engine that understands — which is why it tops the benchmarks instead of just claiming to.It reasons — not just retrieves
Resolves contradictions, tracks temporal change, follows multi-hop relationships, and forgets expired facts automatically. Reasoning is why it wins every benchmark.
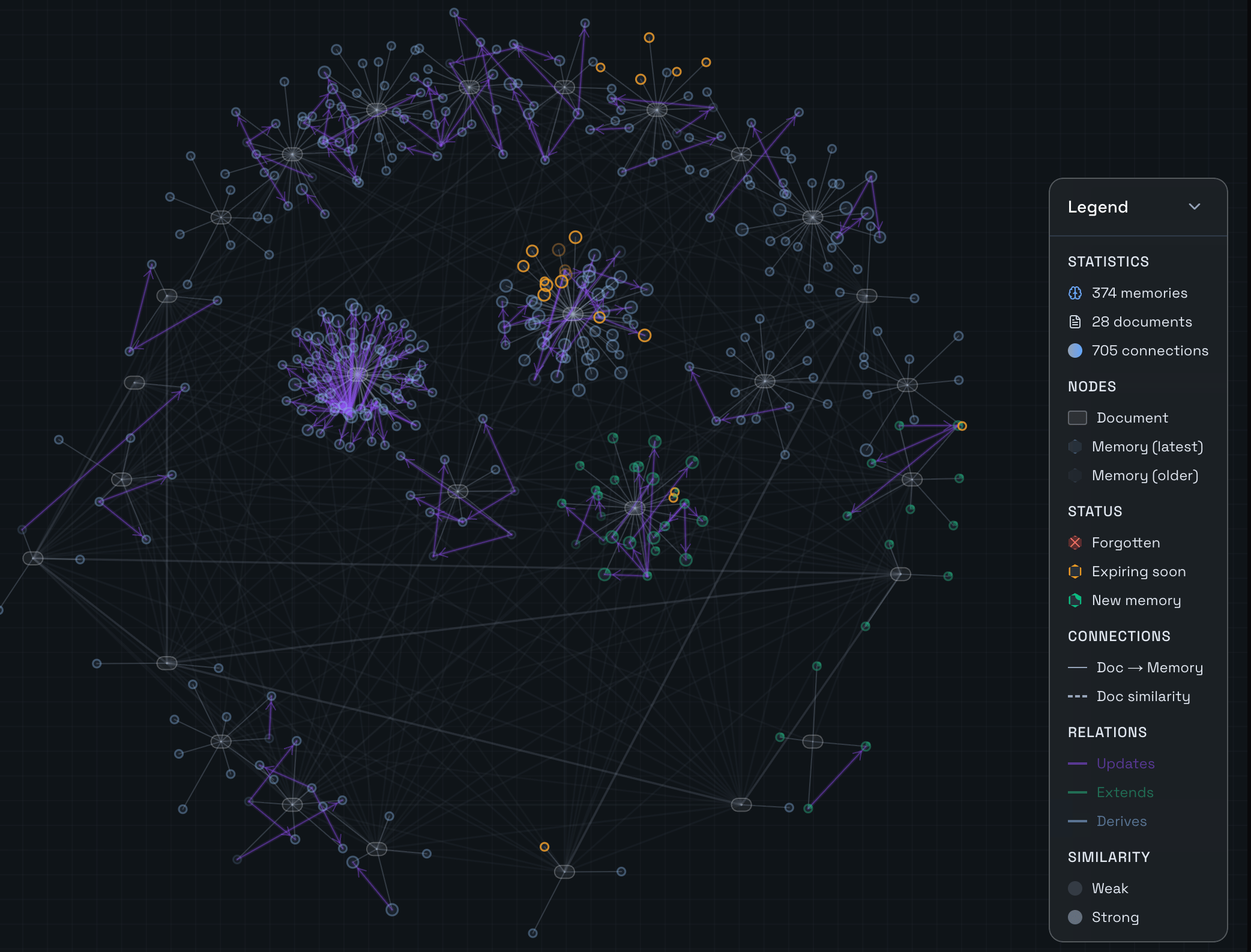
A directed knowledge graph
One evolving directed graph and a single ontology across all your data — not a flat vector store, and not a raw graph you have to traverse yourself.
The whole context stack, one system
Memory, user profiles, hybrid search (RAG), connectors, and file processing — together, sharing one context pool. No stitching five tools together.
Multi-modal — everything in
Text, conversations, PDFs, images (OCR), video (transcription), and code (AST-aware chunking). Upload it and it just works.
Built to build on
One API, plus SDKs, a CLI, a memory filesystem, and MCP. Infrastructure you ship products on — not a closed box.
Run it anywhere
Hosted for zero-ops scale, or the full engine as one self-hosted binary — fully offline if you want, same API either way.
How does it work? (at a glance)
- You send Supermemory text, files, and chats.
- It indexes them intelligently and builds a directed knowledge graph on top of an entity (a user, document, project, or organization).
- At query time, it fetches only the most relevant context and passes it to your models.
Three ways to add context
Memory, profiles, and search all draw from the same context pool for a given user (containerTag) — so they reinforce each other instead of living in silos. Mix and match as your use case needs.
Memory API — learned user context
- Evolve on top of existing context about the user, in real time
- Handle knowledge updates, temporal changes, and contradictions
- Power a user profile that acts as the default context provider for the LLM
User profiles
The evolving context produces a User Profile — the facts your agent should always know, in one ~50ms call:- Static: stable facts the agent should always know.
- Dynamic: episodic context from the last few conversations.
RAG — advanced semantic search
Run hybrid search over the raw content too: advanced metadata filtering, contextual chunking, and reranking — tightly integrated with the memory engine, in a single query.Start building
Quickstart
Make your first API call in minutes.
Add your first memory
Ingest text, files, and conversations into a container.
Search it
Retrieve the most relevant context with hybrid semantic search.
Ways to use Supermemory
The API is the core — but you don’t have to talk to it directly. Reach Supermemory however fits your workflow:SDKs
Official TypeScript and Python SDKs, plus drop-in plugins for the AI SDK, OpenAI, LangChain, and more.
Command line (CLI)
Manage memories, search, and scripting from your terminal — it’s all
npx supermemory.Memory filesystem (SMFS)
Mount a container as a real directory your agent can
ls, cat, and semantically grep.Self-host it
Run the full memory engine on your own machine — one binary, zero config, fully offline.